頂尖棋手在關鍵時刻會切換的兩種模式

在我下棋已超過三十年的經歷裡,聽過最中肯,最有幫助的一段話,就是「比賽的時候,不要總想著找出當前最好的一手,而是要找出確保能贏的下法。」
「什麼確保能贏就好?笑死,對自己要求也太低了吧,我才沒這麼low呢!」

聽到這句建議的當下,我感到有點嗤之以鼻,當時的我深受圍棋動漫「棋靈王」的影響,覺得下棋不就是應該要找出那所謂的“神之一手”才是王道嗎?
直到看了AlphaGo與韓國圍棋大師李世石的人機大戰後,才知道當時的我錯得離譜!

還記得人機大戰的第一盤後半段,AlphaGo在局面領先的情況下,接連走出了幾步弱著。
當時幾乎觀看這盤棋的所有人,都認為AlphaGo失誤了。
直到局面進行到終盤收官階段,大家才驚覺到,原來AlphaGo之前所下的幾步弱著並不是失誤,而是“確保能微幅領先的著手”。
換句話說,當AlphaGo勝率高於某一閾值,它就不再尋求最佳手,而是採用降低波動、壓縮變數的策略穩中求勝。
以數字來表示的話,如果50︰50代表的是平手,那麼只要你能持續保持至少51︰49的局面,就能在確保在不輸棋的前提下,尋求贏棋的契機。
「風險控制」與「穩定輸出」這兩種思考模式,就是人機大戰帶給我最大的啟發。

後來我才理解,這種思維其實正呼應了諾貝爾獎得主Herbert Simon的理論。
他提出了「有限理性(bounded rationality)」與「滿意原則(satisficing)」的概念。
Simon 認為,人們難以在實作中取得全部資訊,也不可能擁有無限的計算能力,因此往往不一定能找到理論上的「最佳解」。
於是,在現實中人們會設定一個「夠好」的標準,也就是所謂的「期望門檻」,當遇到第一個能滿足這個門檻的選項時,就採取行動。
這並不是懶惰,而是在有限時間與資源下的理性抉擇。
特別是在像下棋這樣「分支極多、時間受限」的高不確定決策環境裡,「滿意化」往往比「最大化」更符合現實,也更能持續取勝。
用這個角度重新看AlphaGo的下法,我才恍然大悟。
所謂的「找出最好的一手」,其實就是一種「最大化策略」,也就是不惜代價地追求理論上最優解。
而「確保能贏的下法」,則屬於「滿意化策略」,也就是只要能穩定維持優勢、守住勝率門檻,就不再冒不必要的風險。
雖然「大幅領先」和「微幅領先」到最後的結果都是贏棋,但如果伴隨「大幅領先」而來的是高風險的局面,還不如追求「微幅領先」來得穩健。
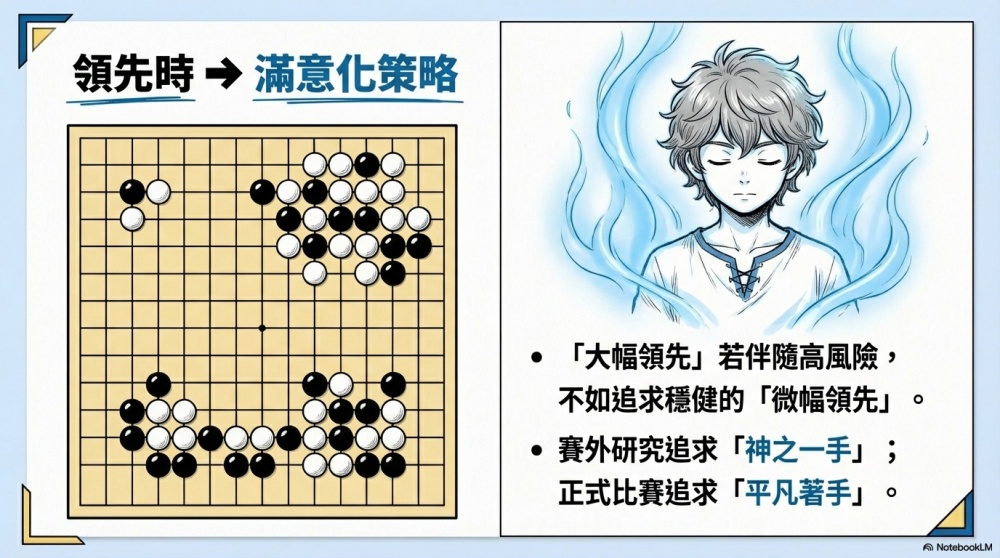
在進行賽外研究的時候,我們可以追求那所謂的「神之一手」;但在正式比賽的當下,請改為追求能一直保持微幅領先的平凡著手。
這不僅是行棋上的策略轉變,更是一種「有限理性」下的成熟抉擇。

前面提及的內容,指的是在你局面佔有優勢的時候,「有限理性」會成為一個很好的策略。
而當局勢對你不利的時候,你的目標將不再是維持現狀,因為維持現狀只會導致穩定地輸掉比賽。
你要思索的是該怎麼下,才能將盤面導向雙方都陌生的高複雜度的戰場。
這個時候,你將不再採用「足夠滿意」的解,而是尋求一個能打破對手滿意狀態的解。
這個解必須讓對手感到不舒服、不安穩,迫使他們從滿意的穩健策略,切換回高壓計算的最大化策略。
當你採取高風險策略時,你是主動創造問題的一方,對手是被動解決問題的一方。
即使仍處於劣勢,但在心理上你已從「守勢」變為「攻勢」。
雖然很冒險,但並非盲目亂下。成熟的棋手會快速評估在所有高風險選項中,哪個選項給對手製造的計算難度最大?
總結來說,「滿意化」是領先者的策略,「最大化」是落後者的武器。

一個頂尖的棋手,其能力不在於固守任一策略,而在於能像前面內容所說的,根據勝率與風險的動態變化,在兩種截然不同的決策模式之間進行靈活、果斷的切換。











一般留言